At the end of my previous post about easily pseudo-localizing WPF applications, I said this post would show how to apply those concepts to a Silverlight application. Unfortunately, I seem to have made an off-by-one error: while this post is related to that topic, it is not the post I advertised. But it seems interesting in its own right, so I hope you enjoy it. :)
Okay, so what does a PNG (Portable Network Graphics) image encoder have to do with pseudo-localizing on the Silverlight platform? Almost nothing - except for the fact that I went above and beyond with my last post and showed how to pseudo-localize not just text, but images as well. It turns out the technique I used for that (reading the System.Drawing.Image instance from the resources class and manipulating its pixels before handing it off to the application) won't work on Silverlight. You see, the System.Drawing namespace/assembly doesn't exist for Silverlight! So although the RESX designer in Visual Studio will happily let you add an image to a Silverlight RESX file, actually doing so results in an immediate compile error: The type or namespace name 'Drawing' does not exist in the namespace 'System' (are you missing an assembly reference?)...
But all is not lost - there are other ways of adding an image to a RESX file! True, the process is a little wonky and cumbersome, but at least it works. However, the resulting resource is exposed as either a byte[] or a Stream instance - both of which are basically just a sequence of bytes. And because there's no SetPixel method for byte arrays, this is a classic "Houston, we have a problem" [sic; deliberately misquoting] moment for my original approach of pseudo-localizing the image by manipulating its pixels... Hum, what's a girl to do?
Well, those bytes do correspond to an encoded image, so it ought to be possible to decode the image - at which point we could wrap it in a WriteableBitmap and do the pixel manipulation via its Pixels property. After that, we could re-encode the altered pixels back to an image file (remember that the resource data is expected to be the encoded bytes of an image) and things should work as seamlessly as they did for the original scenario. And they actually do! Well, on WPF, at least...

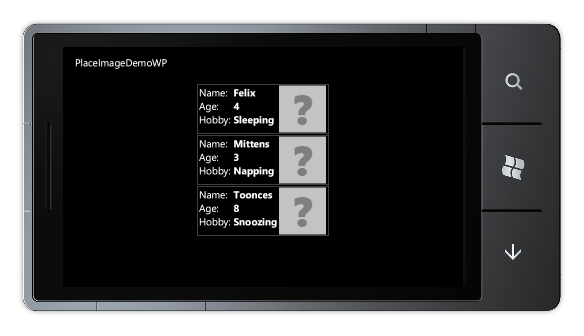
Sample PNG file encoded by PngEncoder
Not on Silverlight, though. Silverlight will get you all the way to the last step, but that's the end of the line: the platform doesn't expose a way to do the re-encoding. :( As you might guess, this is hardly the first time this issue has come up - a quick web search turns up plenty of examples of people wanting to encode images under Silverlight. The typical recommendation is to find (or write) your own image encoder, and so there are a number of examples of Silverlight-compatible image encoders to be found!
So why did I write my own??
Well, because none of the examples I found was quite what I wanted. The most obvious candidate just flat out didn't work; it crashed on every input I gave it. The runner-up (deliberately) took shortcuts for speed and didn't produce valid output. The third option was released under a license I'm not able to work with. And the fourth was part of a much larger image encoding library I didn't feel like pulling apart. Besides, I release full source code on my blog, and I don't want to be in the business of distributing other peoples' code with my samples. A lot of times it's just easier and safer to code something myself - and I've had a lot of great learning experiences as a result! :)
When choosing an image format for re-encoding on the fly, Silverlight makes the decision fairly easy because it supports only two image formats: JPEG and PNG. Because JPEG is a lossy format, it's pretty much a non-starter (we don't want to degrade image quality) and therefore lossless PNG is the obvious choice. Conveniently, the PNG image format is fairly simple - especially if you're willing to punt on (losslessly) compressing the image! All you need to encode a PNG file is a format prefix (8 bytes), a header chunk (5 bytes), an image chunk with the properly encoded pixels, and an end chunk (0 bytes). There's a decent amount of bookkeeping to be done along the way (scanline filtering, compression block creation, two different hash algorithms, etc.), but it's all fairly straightforward. And the PNG specification is well-written and fairly easy to follow - what more could you ask for?
Aside: Giving up on compression may seem like a big deal, but I don't think it is for the scenario at hand. While small file size is important for making the best use of long-term storage, the pseudo-localization scenario creates its PNG file on the fly, loads it, and immediately discards it. The encoded image simply isn't around for very long and so its large size shouldn't matter.
Okay, so PNG encoding isn't rocket science - but I still feel that if I'm going to reinvent the wheel, then at least I should try to contribute something new or interesting to the mix! :)
What I've done here is to use IEnumerable everywhere:
namespace Delay
{
/// <summary>
/// Class that encodes a sequence of pixels to a sequence of bytes representing a PNG file (uncompressed).
/// </summary>
/// <remarks>
/// Reference: http://www.w3.org/TR/PNG/.
/// </remarks>
static class PngEncoder
{
/// <summary>
/// Encodes the specified pixels to a sequence of bytes representing a PNG file.
/// </summary>
/// <param name="width">Width of the image.</param>
/// <param name="height">Height of the image.</param>
/// <param name="pixels">Pixels of the image in ARGB format.</param>
/// <returns>Sequence of bytes representing a PNG file.</returns>
public static IEnumerable<byte> Encode(int width, int height, IEnumerable<int> pixels) { /* ... */ }
}
}
And IEnumerable isn't just for the public API, it's used throughout the code, too! This is the meaning behind the title of this post: giving up on compression is inefficient from a storage space perspective, but operating exclusively on enumerations is very efficient from a memory consumption and a computational efficiency perspective! Because of that, this class can encode a 20-megabyte PNG file without allocating any more memory than it takes to encode a 1-byte PNG file. What's more, no work is done before it needs to be: if you're streaming a PNG file across a slow transport, the file will be read and encoded only as quickly as the receiver consumes the bytes - and if encoding is aborted mid-way for some reason, no unnecessary effort has been wasted!
This efficiency is possible thanks to the way IEnumerable works and the convenience of C#'s yield return which makes it easy to write code that returns an IEnumerable without explicitly implementing IEnumerator. As a result, the code for PngEncoder is clear and linear with no hint (or visible complexity) of the allocation savings or deferred processing that occur under the covers. Instead, everything communicates in terms of byte sequences - translating one sequence to another inline as necessary. For example, every horizontal line of an encoded PNG image is prefixed with a byte indicating which filtering algorithm was used. These filter bytes aren't part of the original pixels that are passed into the Encode call, so they need to be added. What's cool is that it's easy to write a method to do so - and because it takes an IEnumerable input parameter and returns an IEnumerable result, such a method can be trivially "injected" into any data flow!
One particularly handy realization of this technique is demonstrated by a class I called WrappedEnumerable - here's what it looks like to the developer:
/// <summary>
/// Class that wraps an IEnumerable(T) or IEnumerator(T) in order to do something with each byte as it is enumerated.
/// </summary>
/// <typeparam name="T">Type of element being enumerated.</typeparam>
abstract class WrappedEnumerable<T> : IEnumerable<T>, IEnumerator<T>
{
/// <summary>
/// Method called to initialize for a new (or reset) enumeration.
/// </summary>
protected virtual void Initialize() { }
/// <summary>
/// Method called for each byte output by the underlying enumerator.
/// </summary>
/// <param name="value">Next value.</param>
protected abstract void OnValueEnumerated(T value);
}
WrappedEnumerable is useful for PngEncoder because the encoding process makes use of two different hash algorithms: CRC-32 and Adler-32. Long-time readers of this blog know I'm no stranger to hash functions - in fact, I've previously shared code to implement CRC-32 based on the very same PNG specification! But as much as I love .NET's HashAlgorithm, using it here seemed like it might be overkill. HashAlgorithm is ideal for processing large chunks of data at a time, but the sequence-oriented nature of PngEncoder deals with a single byte at a time. So what I did was to create WrappedEnumerable subclasses Crc32WrappedEnumerable and Adler32WrappedEnumerable which override the two methods above to calculate their hash values as the bytes flow through the system! These are both simple classes and work quite well for "injecting" hash math into a data flow. The PNG format puts stores its hash values after the corresponding data, so by the time that value is needed, the relevant data has already flowed through the WrappedEnumerable and the final hash is ready to be retrieved.
However, the same cannot be said of the length fields in the PNG specification... Lengths are stored before the corresponding data, and that poses a distinct problem when you're trying to avoid looking ahead: without knowing what data is coming, it's hard to know how much there is! But I'm able to cheat here: because PngEncoder doesn't compress, it turns out that all the internal lengths can be calculated from the original width and height values passed to the call to Encode! So while this is a bit algorithmically impure, it completely sidesteps the length issue and avoids the need to buffer up arbitrarily long sequences of data just to know how long they are.
Aside: After spending so much time celebrating the IEnumerable way of life, this is probably a good time to highlight one of its subtle risks: multiple enumeration due to deferred execution. Multiple enumeration is something that comes up a lot in the context of LINQ - an IEnumerable<byte> is not the same thing as a byte[]. Whereas it's perfectly reasonable to pass a byte[] off to two different functions to deal with, doing the same thing with an IEnumerable<byte> usually results in that sequence being created and enumerated twice! Depending on where the sequence comes from, this can range from inefficient (a duplication of effort) to catastrophic (it may not be possible to generate the sequence a second time). The topic of multiple enumeration is rich enough to merit its own blog post (here's one and here's another and here's another), and I won't go into it further here. But be on the look-out, because it can be tricky!
Further aside: To help avoid this problem in PngEncoder, I created the TrackingEnumerable and TrackingEnumerator classes in the sample project. These are simple IEnumerable/IEnumerator implementations except that they output a string with Debug.WriteLine whenever a new enumeration is begun. For the purposes of PngEncoder, seeing any more than one of these outputs represents a bug!
In an attempt to ensure that my PngEncoder implementation behaves well and produces valid PNG files, I've written a small collection of automated tests (included with the download). Most of them are concerned with parameter validation and correct behavior with regard to the IEnumerable idiosyncrasies I mentioned earlier, but the one called "RandomImages" is all about output verification. That test creates 25 PNG files of random size and contents, encodes them with PngEncoder, then decodes them with two different decoder implementations (System.Drawing.Bitmap and System.Windows.Media.Imaging.PngBitmapDecoder) and verifies the output is identical to the input. I've also verified that PngEncoder's PNG files can be opened in a variety of different image viewing/editing applications. (Interesting tidbit: Internet Explorer seems to be the strictest about requiring valid PNG files!) While none of this is a guarantee that all images will encode successfully, I'm optimistic typical scenarios will work well for people. :)
[Click here to download the source code for the complete PngEncoder.cs implementation, a simple test application, and the automated test suite.]
At the end of the day, the big question is whether my focus (obsession?) with an IEnumerable-centric implementation was justified. From a practical point of view, you could argue this either way - I happen to think things worked out pretty elegantly, but others might argue the code would be clearer with explicit allocations. I'll claim the memory/computational benefits I describe here are pretty compelling (especially in resource-constrained scenarios like Windows Phone), but others could reasonably argue that naïve consumers of PngEncoder are likely to write their code in a way that negates those benefits (ex: by calling ToArray).
However, I'm not going to spend a lot of time second-guessing myself; I think it was a great experience. :) The following sums up my thoughts on the matter pretty nicely:
The road of life twists and turns and no two directions are ever the same. Yet our lessons come from the journey, not the destination. - Don Williams, Jr.