Preprocessor? .NET don't need no stinkin' preprocessor! [DebugEx.Assert provides meaningful assertion failure messages automagically!]
If you use .NET's Debug.Assert method, you probably write code to validate assumptions like so:
Debug.Assert(args == null);
If the expression above evaluates to false at run-time, .NET immediately halts the program and informs you of the problem:
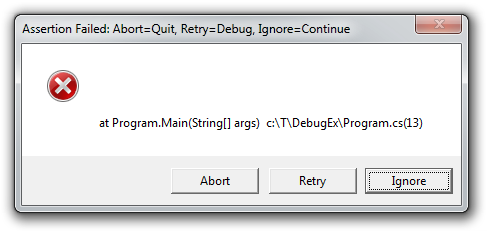
The stack trace can be really helpful (and it's cool you can attach a debugger right then!), but it would be even more helpful if the message told you something about the faulty assumption... Fortunately, there's an overload of Debug.Assert that lets you provide a message:
Debug.Assert(args == null, "args should be null.");
The failure dialog now looks like this:
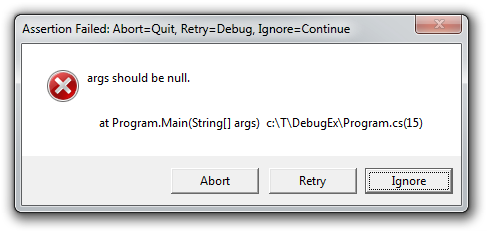
That's a much nicer experience - especially when there are lots of calls to Assert and you're comfortable ignoring some of them from time to time (for example, if a network request failed and you know there's no connection). Some code analysis tools (notably StyleCop) go as far as to flag a warning for any call to Assert that doesn't provide a custom message.
At first, adding a message to every Assert seems like it ought to be pure goodness, but there turn out to be some drawbacks in practice:
-
The comment is often a direct restatement of the code - especially for very simple conditions. Redundant redundancy is redundant, and when I see messages like that, I'm reminded of code comments like this:
i++; // Increment i -
It takes time and energy to type out all those custom messages, and the irony is that most of them will never be seen at all!
Because the code for the condition is often expressive enough as-is, it would be nice if Assert automatically used the code as the message!
Aside: This is hardly a new idea; C developers have been doing this for years by leveraging macro magic in the preprocessor to create a string from the text of the condition.
Further aside: This isn't even a new idea for .NET; I found a couple places on the web where people ask how to do this. And though nobody I saw seemed to have done quite what I show here, I'm sure there are other examples of this technique "in the wild".
As it happens, displaying the code for a condition can be accomplished fairly easily in .NET without introducing a preprocessor! However, it requires that calls to Assert be made slightly differently so as to defer execution of the condition. In a normal call to Assert, the expression passed to the condition parameter is completely evaluated before being checked. But by changing the type of the condition parameter from bool to Func<bool> and then wrapping it in the magic Expression<Func<bool>>, we're able to pass nearly complete information about the expression into the Assert method where it can be used to recreate the original source code at run-time!
To make this a little more concrete, the original "message-less" call I showed at the beginning of the post can be trivially changed to:
DebugEx.Assert(() => args == null);
And the DebugEx.Assert method I've written will automatically provide a meaningful message (by calling the real Debug.Assert and passing the condition and a message):
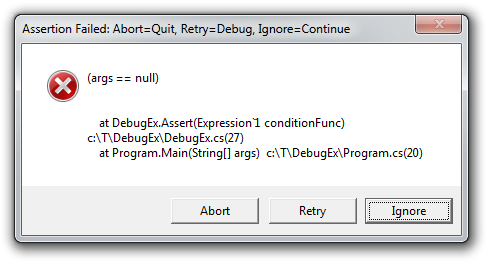
The message above is identical to the original code - but maybe that's because it's so simple... Let's try something more complex:
DebugEx.Assert(() => args.Select(a => a.Length).Sum() == 10);
Becomes:
Assertion Failed: (args.Select(a => a.Length).Sum() == 10)
Wow, amazing! So is it always perfect? Unfortunately, no:
DebugEx.Assert(() => args.Length == 5);
Becomes:
Assertion Failed: (ArrayLength(args) == 5)
The translation of the code to an expression tree and back seems to have lost a little fidelity along the way; the compiler translated the Length access into an expression tree that doesn't map back to code exactly the same. Similarly:
DebugEx.Assert(() => 5 + 3 + 2 >= 100);
Becomes:
Assertion Failed: False
In this case, the compiler evaluated the constant expression at compile time (it's constant, after all!), and the information about which numbers were used in the computation was lost.
Yep, the loss of fidelity in some cases is a bit of a shame, but I'll assert (ha ha!) that nearly all the original intent is preserved and that it's still quite easy to determine the nature of the failing code without having to provide a message. And of course, you can always switch an ambiguous DebugEx.Assert back to a normal Assert and provide a message parameter whenever you want.
DebugEx.Assert was a fun experiment and a great introduction to .NET's powerful expression infrastructure. DebugEx.Assert is a nearly-direct replacement for Debug.Assert and (similarly) applies only when DEBUG is defined, so it costs nothing in release builds. It's worth noting there will be a bit of extra overhead due to the lambda, but it should be negligible - especially when compared to the time you'll save by not having to type out a bunch of unnecessary messages!
If you're getting tired of typing the same code twice, maybe DebugEx.Assert can help!
Notes:
-
The code for
DebugEx.Assertturned out to be simple because nearly all the work is done by theExpression(T)class. The one bit of trickiness stems from the fact that in order to create a lambda to pass as theFunc(T), the compiler creates a closure which introduces an additional class (though they're never exposed to the developer). Therefore, even simple statements like the original example become kind of hard to read:Assertion Failed: (value(Program+<>c__DisplayClass0).args == null).To avoid that problem, I created an ExpressionVisitor subclass to rewrite the expression tree on the fly, getting rid of the references to such extra classes along the way. What I've done with
SimplifyingExpressionVisitoris simple, but seems to work nicely for the things I've tried. However, if you find scenarios where it doesn't work as well, I'd love to know so I can handle them too!