Problem
I spent some time in my last post explaining how Silverlight/WPF Charting takes advantage of an ordered multi-dictionary to improve the performance of various scenarios. I wrote about Charting's use of a custom binary tree implementation and outlined some limitations of that algorithm and our particular implementation of it. In this post, I'm going to explain how we're addressing those limitations for the next release of Charting and share the general purpose code we're using to do it!
The fundamental problem with our current BinaryTree implementation is that offers no guarantee of balance, and can devolve into linear performance even when dealing with fairly typical data. And this isn't an implementation problem - it's an algorithmic one: if you want balancing behavior, you should really use a data structure that balances. (Duh...) One of the most popular data structures for implementing a balanced binary tree is the red-black tree. Red-black trees get their name from the colors they assign to their nodes - which they use to perform various "rotations" on the tree in order to maintain a set of invariants that guarantee the tree remains more-or-less balanced. (I'm not going to go into more detail here; the Wikipedia article is a great resource for learning more.) The "problem" with red-black trees is that they're notoriously tricky to implement correctly - especially the remove scenarios. There are a lot of special cases to deal with, and things can get messy pretty quickly...
Solution
Which is why I was so excited to read about Robert Sedgewick's research paper on "left-leaning red-black trees". (If you want something a little more colorful than a research paper, here's a presentation on the same topic.) Basically, Dr. Sedgewick took advantage of a correspondence between red-black trees and 2-3-4 trees to introduce a constraint (that red nodes must be "left-leaning") which significantly simplifies the overall implementation. This new algorithm sounded perfect for our purposes, and I spent a few bus rides developing a C# implementation of left-leaning red-black trees based on the published research.
But wait! Charting needs an ordered multi-dictionary whereas red-black trees implement a standard dictionary - what gives? Well, do you remember the trick I wrote about in my binary tree post where I figured out that I could turn a standard dictionary into an ordered multi-dictionary by adding a value comparison into the mix? Good, because I've done exactly the same thing here. :)
But this time it's even a little bit better! Instead of storing "identical" nodes next "beside" each other (which is not as easy in a red-black tree), I realized that I could collapse all duplicate nodes into the same node by adding a Sibling count to the Node structure. This makes duplicate nodes really easy to deal with because the standard add and remove code stays exactly the same until the very end when it checks for siblings.
But wait - there's more. :) Because it was so easy to implement the ordered multi-dictionary Charting needed, I decided to make my LeftLeaningRedBlackTree implementation both an ordered multi-dictionary and a normal dictionary! You can choose which one you want by passing in either key+value comparison functions to the constructor (to create an ordered multi-dictionary) or just a key comparison function (to create a standard dictionary). All the class's properties and methods work exactly the same in both modes, so switching between them is easy! (To make it even easier, I've added two trivial helper methods to simplify the standard dictionary scenarios: Remove(key) and GetValueForKey(key).)
Performance
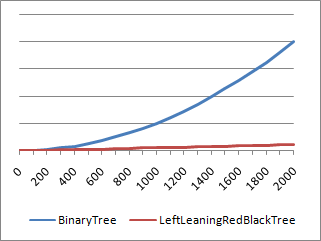
Okay, so this is all well and good, but the real question is whether LeftLeaningRedBlackTree runs faster than BinaryTree or not. Well, if you looked at the graph above comparing the elapsed time (vertical axis) of the two solutions for different node counts (horizontal axis), then you already know the answer. LeftLeaningRedBlackTree is a clear win for the tested scenario (which was sequential adds, a bunch of min/max search operations, then sequential removes - typical Charting behavior). Okay, so once you've decided that LeftLeaningRedBlackTree is a win when node counts start getting large, the next question is how the two implementations compare for low node counts. Because the scale of the previous graph is large and could be obscuring some detail in the low range, let's specifically measure the performance for small numbers of nodes:
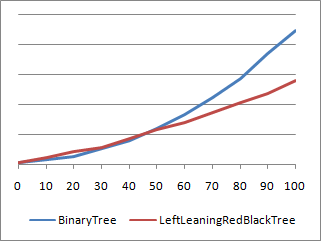
And there you have it: BinaryTree beats LeftLeaningRedBlackTree when the node count is close to 20. Which isn't very surprising when you think about it - for small numbers of nodes, the unbalance of BinaryTree is not yet significant enough to outweigh the overhead that LeftLeaningRedBlackTree incurs from its balancing process. But does this particular region of performance inversion really matter? Not so much - the range where BinaryTree wins is very small, the difference in timings is small, and the impact of sorting on performance at those node counts is basically insignificant. So the next version of Charting doesn't bother trying to pick the best sorting algorithm for different scenarios - it uses LeftLeaningRedBlackTree for everything. And you'll be glad it does when your node count starts growing! :)
Aside: There is a scenario where BinaryTree beats LeftLeaningRedBlackTree even at large node counts. Specifically, if the original data is already completely random, then BinaryTree naturally ends up nicely balanced as a direct consequence of that randomness - and it didn't need to spend any cycles making itself that way! LeftLeaningRedBlackTree doesn't know the data is random and spends cycles balancing itself unnecessarily. However, this performance delta between the algorithms doesn't diverge like in the charts above - LeftLeaningRedBlackTree has a consistent ~35% overhead across the board. It's been said that you never get something for nothing - and this overhead is just part of the cost of having guaranteed balancing behavior across all inputs.
Testing
Okay, so it's faster - but is it correct? Yes, I'm prepared to suggest that it is - and I happen to have a set of automated test cases to back my claim up! :) The tests I've written pick a random number of elements across randomly sized key and value spaces, add all these random pairs to the tree, make sure everything's behaving correctly, and then remove them all in random order. After each add or remove, the complete state of the entire tree is checked against a separate algorithm. And all the while LeftLeaningRedBlackTree is running its own internal code to ensure the invariants of a left-leaning red-black tree are maintained at all times.
I call this whole thing a "scenario". I've found that 100% code coverage is achieved after running just 1 or 2 scenarios; 40 scenarios is all it takes to exercise the set of problematic corner cases I've seen. Well, the automated tests run 1000 scenarios - 250 known scenarios against a normal dictionary, 250 known scenarios against an ordered multi-dictionary, 250 random ones on a normal dictionary, and 250 random ones on an ordered multi-dictionary. Whew!
Of course, no code is ever perfect - but I'm pretty happy with the level of coverage here and optimistic that it's helped squash the bugs that matter.
API
You might expect LeftLeaningRedBlackTree to implement IDictionary<TKey, TValue> - but it doesn't. However, it does have an API that strongly resembles that interface, so it should look pretty familiar. For example, Add looks exactly the same and the single-parameter form of Remove (for normal dictionary mode) is exactly the same as well. Ordered multi-dictionary mode necessitates a two-parameter form of Remove, but it's just what you'd expect. Clear and Count (via IDictionary's base class ICollection<T>) are identical as well.
However, things start to diverge a bit after that. Instead of ICollection<T> properties for Keys and Values (which may be unnecessarily costly to compute if the caller only needed a few of the elements), there are IEnumerable<T> methods GetKeys and GetValuesForAllKeys. It's the same idea, but more efficient thanks to being sequence-based! The array accessor (this[T]) is deliberately absent because it doesn't make much sense for the ordered multi-dictionary mode - I'd rather things be more explicit via Add or GetValueForKey/GetValuesForKey. The latter of those last two methods works in both modes; the first is available as a simplification for normal dictionary mode (and throws KeyNotFoundException for consistency with IDictionary implementations). ContainsKey and TryGetValue are both absent - and trivial to add if you want them. As for the rest of the IDictionary<T>/ICollection<T>/IEnumerable<T>/IEnumerable properties and methods, they either don't make sense on an ordered multi-dictionary or are easy enough to add. And finally, the API is rounded out by the MinimumKey and MaximumKey properties - specifically implemented for efficiency because Charting makes such heavy use of them.
In case that was all just a confusing jumble of class names and interfaces, here's what it looks like in code:
/// <summary>
/// Implements a left-leaning red-black tree.
/// </summary>
/// <remarks>
/// Based on the research paper "Left-leaning Red-Black Trees"
/// by Robert Sedgewick. More information available at:
/// http://www.cs.princeton.edu/~rs/talks/LLRB/RedBlack.pdf
/// http://www.cs.princeton.edu/~rs/talks/LLRB/08Penn.pdf
/// </remarks>
/// <typeparam name="TKey">Type of keys.</typeparam>
/// <typeparam name="TValue">Type of values.</typeparam>
public class LeftLeaningRedBlackTree<TKey, TValue>
{
/// <summary>
/// Initializes a new instance of the LeftLeaningRedBlackTree class implementing a normal dictionary.
/// </summary>
/// <param name="keyComparison">The key comparison function.</param>
public LeftLeaningRedBlackTree(Comparison<TKey> keyComparison)
/// <summary>
/// Initializes a new instance of the LeftLeaningRedBlackTree class implementing an ordered multi-dictionary.
/// </summary>
/// <param name="keyComparison">The key comparison function.</param>
/// <param name="valueComparison">The value comparison function.</param>
public LeftLeaningRedBlackTree(Comparison<TKey> keyComparison, Comparison<TValue> valueComparison)
/// <summary>
/// Adds a key/value pair to the tree.
/// </summary>
/// <param name="key">Key to add.</param>
/// <param name="value">Value to add.</param>
public void Add(TKey key, TValue value)
/// <summary>
/// Removes a key (and its associated value) from a normal (non-multi) dictionary.
/// </summary>
/// <param name="key">Key to remove.</param>
/// <returns>True if key present and removed.</returns>
public bool Remove(TKey key)
/// <summary>
/// Removes a key/value pair from the tree.
/// </summary>
/// <param name="key">Key to remove.</param>
/// <param name="value">Value to remove.</param>
/// <returns>True if key/value present and removed.</returns>
public bool Remove(TKey key, TValue value)
/// <summary>
/// Removes all nodes in the tree.
/// </summary>
public void Clear()
/// <summary>
/// Gets a sorted list of keys in the tree.
/// </summary>
/// <returns>Sorted list of keys.</returns>
public IEnumerable<TKey> GetKeys()
/// <summary>
/// Gets the value associated with the specified key in a normal (non-multi) dictionary.
/// </summary>
/// <param name="key">Specified key.</param>
/// <returns>Value associated with the specified key.</returns>
public TValue GetValueForKey(TKey key)
/// <summary>
/// Gets a sequence of the values associated with the specified key.
/// </summary>
/// <param name="key">Specified key.</param>
/// <returns>Sequence of values.</returns>
public IEnumerable<TValue> GetValuesForKey(TKey key)
/// <summary>
/// Gets a sequence of all the values in the tree.
/// </summary>
/// <returns>Sequence of all values.</returns>
public IEnumerable<TValue> GetValuesForAllKeys()
/// <summary>
/// Gets the count of key/value pairs in the tree.
/// </summary>
public int Count
/// <summary>
/// Gets the minimum key in the tree.
/// </summary>
public TKey MinimumKey
/// <summary>
/// Gets the maximum key in the tree.
/// </summary>
public TKey MaximumKey
}
Debugging
At this point, I'm reasonably confident that LeftLeaningRedBlackTree behaves correctly - but that wasn't always the case! :) Three particular debugging aids served me well and I'd like to call them out (Note: to enable the bottom two debugging aids, you need to uncomment the line #define DEBUGGING at the top of LeftLeaningRedBlackTree.cs):
- The first is a standard .NET technique, but one many people don't seem to be familiar with: DebuggerDisplayAttribute. Specifically, this attribute improves the debugging experience by turning the visual representation of a node from
{LeftLeaningRedBlackTree<int,int>.Node} into Key=4, Value=15, Siblings=0. Granted, it's the same information you'd get by expanding to display the node's properties, but it's automatically used in the Autos and Watch windows as well as by tooltips! What's more, this is easy to enable for any class - just provide a customized format string like this: "Key={Key}, Value={Value}, Siblings={Siblings}".
-
Both LeftLeaningRedBlackTree and its private Node class expose a string property that returns an HTML representation of the tree/node and its children. Here's what it looks like when viewed with Visual Studio's built-in "HTML Visualizer" for strings:
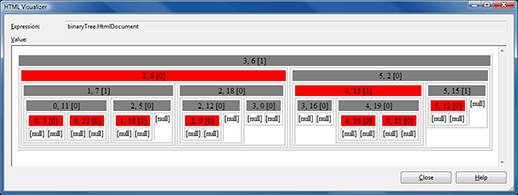
More than just a cool trick, the HtmlDocument and HtmlFragment properties are an invaluable resource for visualizing the many rotations/manipulations of the tree as it balances itself. After you've stared at this kind of stuff for a while, you start to develop a sense of what looks wrong - and this visualization makes finding algorithmic problems quite a bit easier than if the in-memory representation of the tree was all you had!
- When enabled for debugging, the
AssertInvariants method gets called at the end of every method that manipulates the tree. The purpose of this method is to ensure the basic requirements of a left-leaning red-black tree are maintained - specifically, it Asserts that the following conditions are true every time it's called:
- Root node is black
- Every path from the root to leaf nodes contains the same number of black nodes
- Left node is less
- Right node is greater
- Both children of a red node are black
- Nodes are always left-leaning
- No consecutive red nodes
Summary
LeftLeaningRedBlackTree has been a fun project and I'm glad to be able to leverage it to help make significant improvements to Charting's performance for some very real customer scenarios. I'd like to extend my thanks to Dr. Sedgewick for his research in this area and express my hope that others will be able to take advantage of
LeftLeaningRedBlackTree to improve the performance of their own applications. As always, if you run into any problems, please let me know - any errors here are my fault, not anyone else's!
:)
[Please click here to download the source code for LeftLeaningRedBlackTree, its test application, unit tests, and the comparison project.]