"If you can't measure it, you can't manage it." [A brief analysis of markdownlint rule popularity]
From time to time, discussions of a markdownlint rule come up where the popularity of one of the rules is questioned.
There are about 45 rules right now, so there's a lot of room for debate about whether a particular one goes too far or isn't generally applicable.
By convention, all rules are enabled for linting by default, though it is easy to disable any rules that you disagree with or that don't fit with a project's approach.
But until recently, I had no good way of knowing what the popularity of these rules was in practice.
If only there were an easy way to collect the configuration files for the most popular repositories in GitHub, I could do some basic analysis to get an idea what rules were used or ignored in practice.
Well, that's where Google's BigQuery comes in - specifically its database of public GitHub repositories that is available for anyone to query.
I developed a basic understanding of the database and came up with the following query to list the most popular repositories with a markdownlint configuration file:
SELECT files.repo_name
FROM `bigquery-public-data.github_repos.files` as files
INNER JOIN `bigquery-public-data.github_repos.sample_repos` as repos
ON files.repo_name = repos.repo_name
WHERE files.path = ".markdownlint.json" OR files.path = ".markdownlint.yaml"
ORDER BY repos.watch_count DESC
LIMIT 100
Aside: While this resource was almost exactly what I needed, it turns out the data that's available is off by an order of magnitude, so this analysis is not perfect. However, it's an approximation anyway, so this should not be a problem. (For context, follow this Twitter thread with @JustinBeckwith.)
The query above returns about 60 repository names.
The next step was to download and process the relevant configuration files and output a simple CSV file recording which repositories used which rules (based on configuration defaults, customizations, and deprecations).
This was fairly easily accomplished with a bit of code I've published in the markdownlint-analyze-config repository.
You can run it if you'd like, but I captured the output as of early October, 2020 in the file analyze-config.csv for convenience.
Importing that data into the Numbers app and doing some simple aggregation produced the following representation of how common each rule is across the data set:
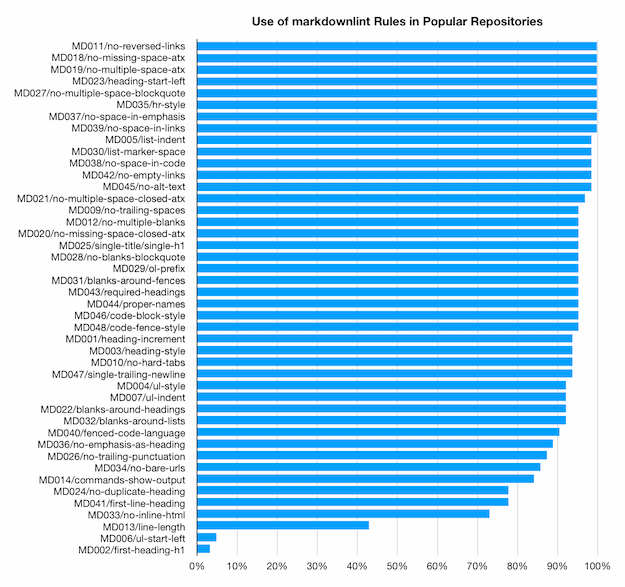
Some observations:
- There are 8 rules that are used by every project whose data is represented here. These should be uncontroversial. Good job, rules!
- The two rules at the bottom with less than 5% use are both deprecated because they have been replaced by more capable rules. It's interesting some projects have explicitly enabled them, but they can be safely ignored.
- More than half of the rules are used in at least 95% of the scenarios. These seem pretty solid as well, and are probably not going to see much protest.
- All but 4 (of the non-deprecated) rules are used in at least 80% of the scenarios. Again, pretty strong, though there is some room for discussion in the lower ranges of this category.
- Of those 4 least-popular rules that are active, 3 are used between 70% and 80% of the time. That's not shabby, but it's clear these rules are checking for things that are less universally applicable and/or somewhat controversial.
- The least popular (non-deprecated) rule is
MD013/line-lengthat about 45% popularity. This is not surprising, as there are definitely good arguments for and against manually wrapping lines at an arbitrary column. This rule is already disabled by default for the VS Codemarkdownlintextension because it is noisy in projects that use long lines (where nearly every line could trigger a violation).
Overall, this was a very informative exercise. The data source isn't perfect, but it's a good start and I can always rerun the numbers if I get a better list of repositories. Rules seem to be disabled less often in practice than I would have guessed. This is nice to see - and a good reminder to be careful about introducing controversial rules that many people end up wanting to turn off. The next time a discussion about rule popularity comes up, I'll be sure to reference this post!