"Make things as simple as possible, but not simpler." [ManagedMsiExec sample app shows how to use the Windows Installer API from managed code]
Windows Installer is the installation and configuration service used by Windows to add and remove applications. (For more information, Wikipedia has a great overview of Windows Installer, covering products, components, setup phases, permissions, etc..) In addition to exposing a rich, native API, Windows Installer comes with msiexec.exe, a command-line tool that offers fine-grained control over the install/uninstall process.
I wanted to familiarize myself with the use of the Windows Installer API from .NET, so I wrote a wrapper class to expose it to managed applications and then a simple program to exercise it. Unlike msiexec.exe which can do all kinds of things, my ManagedMsiExec supports only UI-less install and uninstall of a .MSI Windows Installer package (i.e., /quiet mode). By default, ManagedMsiExec provides simple status reporting on the command line and renders a text-based progress bar that shows how each phase is going. In its "verbose" mode, ManagedMsiExec outputs the complete set of status/progress/diagnostic messages generated by Windows Installer (i.e., /l*) so any problems can be investigated.
Aside: Although I haven't tested ManagedMsiExec exhaustively, it's fundamentally just a thin wrapper around Windows Installer, so I'd expect it to work for pretty much any MSI out there.
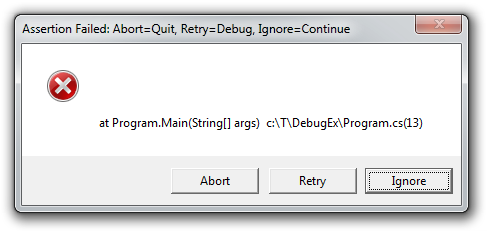
Here's how it looks when run:
C:\T>ManagedMsiExec SYNTAX: ManagedMsiExec <--Install|-i|--Uninstall|-u> Package.msi [--Verbose|-v] Windows Installer result: 87 (INVALID_PARAMETER)
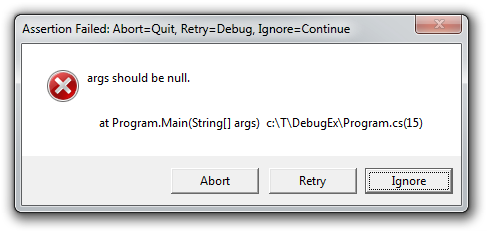
Doing a simple install:
C:\T>ManagedMsiExec -i Package.msi ManagedMsiExec: Installing C:\T\Package.msi Windows Installer result: 0 (SUCCESS)
Doing a simple uninstall:
C:\T>ManagedMsiExec -u Package.msi ManagedMsiExec: Uninstalling C:\T\Package.msi Windows Installer result: 0 (SUCCESS)
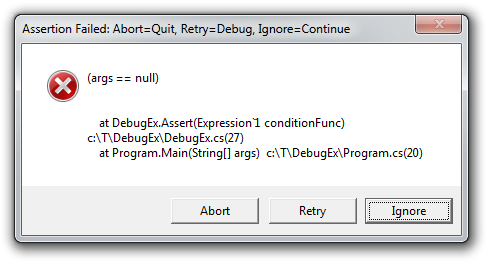
Using verbose mode to diagnose a failure:
C:\T>ManagedMsiExec -u Package.msi -v
ManagedMsiExec: Uninstalling C:\T\Package.msi
ACTIONSTART: Action 18:31:21: INSTALL.
INFO: Action start 18:31:21: INSTALL.
COMMONDATA: 1: 0 2: 1033 3: 1252
PROGRESS:
PROGRESS: 1: 2 2: 189440
COMMONDATA: 1: 0 2: 1033 3: 1252
INFO: This action is only valid for products that are currently installed.
C:\T\Package.msi
COMMONDATA: 1: 2 2: 0
COMMONDATA: 1: 2 2: 1
INFO: DEBUG: Error 2755: Server returned unexpected error 1605 attempting to
install package C:\T\Package.msi.
ERROR: The installer has encountered an unexpected error installing this package.
This may indicate a problem with this package. The error code is 2755.
INFO: Action ended 18:31:21: INSTALL. Return value 3.
TERMINATE:
Windows Installer result: 1603 (INSTALL_FAILURE)
Of note:
-
Msi.cs, the class containing a set of .NET platform invoke definitions for interoperating with the nativeMSI.dllthat exposes Windows Installer APIs. The collection of functions and constants in this file is not comprehensive, but it covers enough functionality to get simple scenarios working. Most of the definitions are straightforward, and all of them have XML documentation comments (via MSDN) explaining their purpose. For convenience, many of the relevant Windows error codes fromwinerror.hare exposed by theERRORenumeration. -
ManagedMsiExec.cs, the sample application itself which works by calling the relevantMsiAPIs in the right order. Conveniently, a complete install can be done in as few as three calls: MsiOpenPackage, MsiDoAction, and MsiCloseHandle (with MsiSetProperty an optional fourth for uninstall or customization). To provide a better command-line experience, the default UI for status reporting is customized via MsiSetInternalUI, MsiSetExternalUI, and MsiSetExternalUIRecord. Implementing the handler for aMsiSetExternalUIcallback is easy because it is passed pre-formatted strings; parsing record structures in the handler for theMsiSetExternalUIRecordcallback requires a few more API calls (and a closer reading of the documentation!).
Note: When providing delegates to theMsiSetExternalUIandMsiSetExternalUIRecordmethods, it's important to ensure they won't be garbage collected while still in use (or else the application will crash!). Because the managed instances are handed off to native code and have a lifetime that extends beyond the function call itself, it's necessary to maintain a reference for the life of the application (or until the callback is unregistered). A common technique for maintaining such a reference is the GC.KeepAlive method (thoughManagedMsiExecsimply stores its delegate references in a static member for the same effect). Conveniently, the callbackOnCollectedDelegate managed debugging assistant can help identify lifetime problems during debugging
The introduction of Windows Installer helped unify the way applications install on Windows and encapsulates a great deal of complexity that installers previously needed to deal with. The openness and comprehensiveness of the Windows Installer native API makes it easy for applications to orchestrate installs directly, and the power of .NET's interoperability support makes it simple for managed applications to do the same.
The Msi class I'm sharing here should allow developers to get started with the Windows Installer API a bit more simply - as the ManagedMsiExec sample demonstrates. The wrapper class and the sample are both pretty straightforward - I hope they're useful, informative, or at least somewhat interesting!