Bringing more HTML to Silverlight [HtmlTextBlock improvements]
I blogged about my HtmlTextBlock implementation for Silverlight a few days ago. In that post I described HtmlTextBlock as a "plug-compatible" replacement for TextBlock that knows how to take simple HTML (technically XHTML) and display it in a manner that fairly closely approximates how a web browser does. The responses I've gotten suggest HtmlTextBlock is somewhat popular, so I've spent a bit of time improving upon the original implementation. The HtmlTextBlock demonstration and source code linked to by my earlier post have been updated, so feel free to play along as you read the notes:
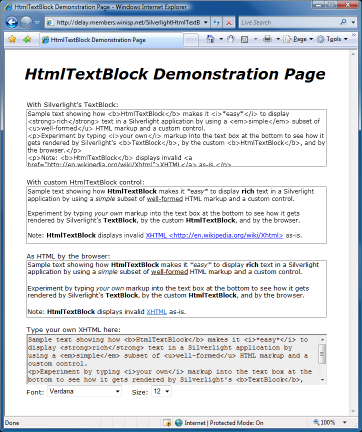
Notes:
- I loved the simplicity of using an XmlReader to parse the input to HtmlTextBlock, but I worried that the prevalence of non-XHTML would limit the usefulness of HtmlTextBlock. For example, the following invalid XHTML would fail to parse correctly:
foo<b>bar</i>baz. During an informal discussion, Ted Glaza suggested using the browser's Document Object Modelto do the parsing of invalid XHTML - great idea! :)- So now when its
Textproperty is set, HtmlTextBlock first treats the input as valid XHTML and tries to parse it with XmlReader. This is the most efficient code path and should be successful for any valid XHTML input. - However, if the input can't be parsed in that manner, HtmlTextBlock uses the objects in Silverlight's
System.Windows.Browsernamespace to dynamically insert the provided text into the host browser's DOM, run some JavaScript code to transform the input into valid XHTML, then extract and parse the transformed text with XmlReader as before. - Two techniques are tried:
- The first method works in browsers that return XHTML for an element's
innerHTMLproperty even if the contents of the element are not valid XHTML (ex: Firefox) and simply inserts and retrieves XHTML from theinnerHTMLproperty. - The second method works in browsers that return the contents of an element as-is (ex: Internet Explorer (though it works fine in Firefox, too)) by walking the node's
.firstChild/.nextSibling/.nodeNametree and manually building up the corresponding XHTML as the nodes of the tree are visited. The results of this method appear ideal in most scenarios, though it's possible to come up with edge cases where its output is slightly different from that of the browser itself (Internet Explorer):foo<b><i>bar</b>baz.
- The first method works in browsers that return XHTML for an element's
- Strangely, BOTH browsers prefer <br> to <br/>, going as far as transforming the latter into the former despite the fact that doing so creates invalid XHTML!
- If all parsing attempts fail, the supplied text is used as-is with no formatting applied.
</div><script>alert('Script code running!');</script>. As such, the new DOM parsing behavior is disabled by default and can be enabled by setting theUseDomAsParserproperty of HtmlTextBlock for scenarios when the input text is known to be safe. - So now when its
- A kind reader informed me that an HtmlTextBlock created in code (vs. in XAML as my sample demonstrated) did not seem to do text wrapping properly. The problem was caused by the difference in when the
Control.Loadedevent fires in the two scenarios. The fix is a simple change toHandleLoadedthat skips sizing the contained TextBlock if the HtmlTextBlock hasn't been sized itself. Additionally, the sample code now demonstrates how to create a HtmlTextBlock in code - just#define CREATE_IN_CODEto see how. - Because HtmlTextBlock used
boolvariables to track the bold/italic/underline states, nesting a style caused that style to be prematurely removed. Specifically, the following scenario would not display properly:normal <b>bold <b>also bold</b> still bold</b> normal. HtmlTextBlock now handles nesting properly by usingintvariables. - I mentioned last time that making HtmlTextBlock adhere to all the individual browser quirks would be a daunting task. For fun, here's a simple input to demonstrate the point:
<p>hello world</p>. Firefox (and HtmlTextBlock) leaves some space above the text because of the <p> element; Internet Explorer does not. :)
In its introductory post, I said that HtmlTextBlock is obviously nothing like a complete HTML rendering engine - and that statement remains true today. However, by taking advantage of the host browser's DOM to transform invalid XHTML input, HtmlTextBlock is much more flexible than it used to be. That - and a few fixes - makes it an even more compelling option for rich text display in Silverlight!