Creating something from nothing, asynchronously [Developer-friendly virtual file implementation for .NET improved!]
Last week I posted the code for VirtualFileDataObject, an easy-to-use implementation of virtual files for .NET and WPF. This code implements the standard IDataObject COM interface for drag-and-drop and clipboard operations and is specifically targeted at scenarios where an application wants to allow the user to drag an element to a folder and create a file (or files) dynamically on the drop/paste. The standard .NET APIs for drag-and-drop don't support this scenario, so VirtualFileDataObject ended up being a custom implementation of the System.Runtime.InteropServices.ComTypes.IDataObject interface. Fortunately, the specifics aren't too difficult, and a series of posts by Raymond Chen paved the way (in native code).
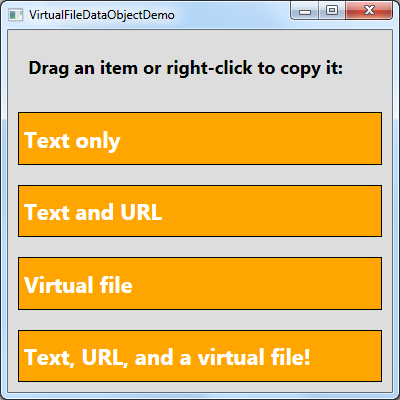
If you read my previous post, you may recall there was an issue with the last scenario of the sample: the application became unresponsive while data for the virtual file was downloading from the web. While this unresponsiveness won't be a noticeable for scenarios involving local data, scenarios that create large files or hit the network are at risk. Well, it's time to find a solution!
And we don't have to look far: the answer is found in the MSDN documentation for Transferring Shell Objects with Drag-and-Drop and the Clipboard under the heading Using IAsyncOperation. As you might expect, we're not the first to notice this behavior; the IAsyncOperation interface exists to solve this very problem. So it seems like things ought to be easy - let's just define the interface, implement its five methods (none of which are very complicated), and watch as the sample application stays responsive during the time-consuming download...
FAIL.
Okay, so that didn't work out quite how we wanted it to. Maybe we defined the interface incorrectly? Maybe we implemented it incorrectly? Or maybe Windows just doesn't support this scenario??
No, no, and no. We've done everything right - it's the platform that has betrayed us. System.Runtime.InteropServices.ComTypes.IDataObject instance in a System.Windows.DataObject wrapper. Because this wrapper object doesn't implement or forward IAsyncOperation, it's as if the interface doesn't exist!
Aside: I have the fortune of working with some of the people who wrote this code in the first place, and I asked why this extra level of indirection was necessary. The answer is that it probably isn't - or at least nobody remembers why it's there or why it couldn't be removed now. So the good news is they'll be looking at changing this behavior in a future release of WPF. The bad news is that the change probably won't happen in time for the upcoming WPF 4 release.
Be that as it may, it looks like we're going to need to call the COM DoDragDrop function directly. Fortunately, there's not much that happens between WPF's DragDrop.DoDragDrop and COM's DoDragDrop, so there's not much we have to duplicate. That said, we do need to define the IDropSource interface and write a custom DropSource implementation of its two methods. The nice thing is that both methods are pretty simple and straightforward, so our custom implementation can be private. (And for simplicity's sake, we're not going to bother raising DragDrop's (Preview)GiveFeedbackEvent or (Preview)QueryContinueDragEvent events.)
Because we've been careful to define the VirtualFileDataObject.DoDragDrop replacement method with the same signature as the DoDragDrop method it's replacing, updating the sample to use it is trivial. So run the sample again, and - BAM - no more unresponsive window during the transfer! (For real, this time.) You can switch to the window, resize it, drag it, etc. all during the creation of the virtual file.
But now we've got a bit of a dilemma: if things are happening asynchronously, how can we tell when they're done? The answer lies with the StartOperation and EndOperation methods of the IAsyncOperation interface. Per the interface contact, these methods are called at the beginning/end of the asynchronous operation. So if we just add another constructor to the VirtualFileDataObject class, we can wire things up in the obvious manner:
/// <summary> /// Initializes a new instance of the VirtualFileDataObject class. /// </summary> /// <param name="startAction">Optional action to run at the start of the data transfer.</param> /// <param name="endAction">Optional action to run at the end of the data transfer.</param> public VirtualFileDataObject(Action startAction, Action endAction)
Well, almost... The catch is that while VirtualFileDataObject now supports asynchronous mode, there's no guarantee that the drop target will use it. Additionally, the developer may have specifically set the VirtualFileDataObject.IsAsynchronous property to false to disable asynchronous mode. And when you're in synchronous mode, there aren't any handy begin/end notifications to rely on...
So I've added support to VirtualFileDataObject for calling the begin/end actions in synchronous mode based on some semi-educated guesses. In my testing, the notifications during synchronous mode behave as identically as possible to those in asynchronous mode. Granted, in some scenarios startAction may run a little earlier in synchronous mode than it would have for asynchronous mode - but as far as the typical developer is concerned, VirtualFileDataObject offers the same handy behavior for both modes!
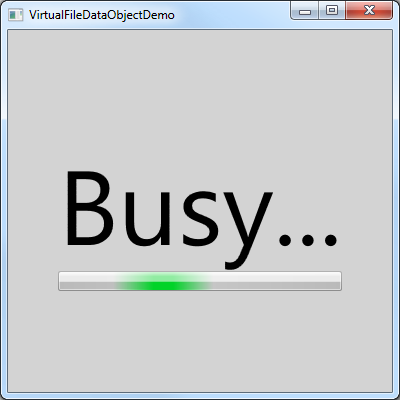
Let's celebrate by updating the sample to show a simple busy indicator during the download:
Code-wise, once we've updated the call to DoDragDrop:
VirtualFileDataObject.DoDragDrop(dragSource, virtualFileDataObject, DragDropEffects.Copy);
Everything else stays the same except for the constructor:
var virtualFileDataObject = new VirtualFileDataObject( // BeginInvoke ensures UI operations happen on the right thread () => Dispatcher.BeginInvoke((Action)(() => BusyScreen.Visibility = Visibility.Visible)), () => Dispatcher.BeginInvoke((Action)(() => BusyScreen.Visibility = Visibility.Collapsed)));
The BusyScreen variable above corresponds to a new element in the sample application that provides the simple "Busy..." UI shown above. In real life, we'd probably use MVVM and a bool IsBusy property on our data model to trigger this, but for a sample application, toggling Visibility works fine. Because all the hard work is done by the VirtualFileDataObject class [you're welcome!
Which is the way it should be!
[Click here to download the complete code for VirtualFileDataObject and the sample application.]
PS - I have one more post planned on this topic demonstrating something I haven't touched on yet to help applications coordinate better with the shell. Stay tuned...