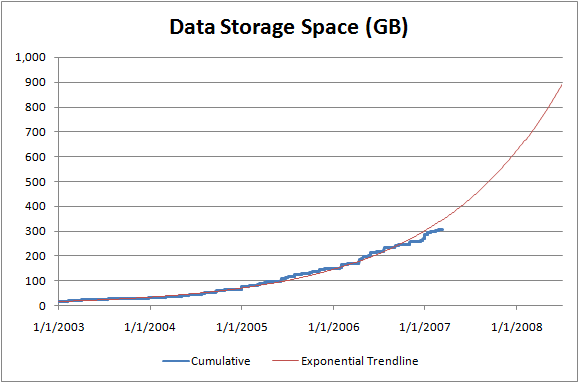
Computing the size of your boat [Sample code to help analyze storage space requirements]
Yesterday I mentioned a quick C# program I wrote to help analyze storage space requirements. There was some interest in how that program worked, so I'm posting the complete source code for anyone to use.
using System;
using System.Collections.Generic;
using System.IO;
class SizeOfFilesCreatedOnDate
{
private const string outputFileName = "SizeOfFilesCreatedOnDate.csv";
static void Main(string[] args)
{
// Create a dictionary to hold the date/size pairs (sorted for subsequent output)
SortedDictionary<DateTime, long> sizeOfFilesCreatedOnDate = new SortedDictionary<DateTime, long>();
// Tally the contents of each specified directory
// * If no command-line argument was given, default to the current directory
if (0 == args.Length)
{
args = new string[] { Environment.CurrentDirectory };
}
foreach (string directory in args)
{
AddDirectoryContents(directory, ref sizeOfFilesCreatedOnDate);
}
// Output all date/size pairs to a CSV file in the current directory
using (StreamWriter writer = File.CreateText(outputFileName))
{
writer.WriteLine("Date,Size,Cumulative");
long cumulative = 0;
foreach (DateTime date in sizeOfFilesCreatedOnDate.Keys)
{
long size = sizeOfFilesCreatedOnDate[date];
cumulative += size;
writer.WriteLine("{0},{1},{2}", date.ToShortDateString(), size, cumulative);
}
}
Console.WriteLine("Output: {0}", outputFileName);
}
private static void AddDirectoryContents(string directory, ref SortedDictionary<DateTime, long> sizeOfFilesCreatedOnDate)
{
// Display status
Console.WriteLine("Scanning: {0}", directory);
// Tally each child file in the parent directory
foreach (string file in Directory.GetFiles(directory))
{
// Get a FileInfo for the file
FileInfo fileInfo = new FileInfo(file);
// Get the creation time of the file
// * If last write < creation, then the file was moved at least once; use the earlier date
// * The difference between local/UTC (~hours) is unimportant at this scale (~years); use local
DateTime date = fileInfo.CreationTime.Date;
if (fileInfo.LastWriteTime.Date < date)
{
date = fileInfo.LastWriteTime.Date;
}
// Update the relevant date/size pair
long size;
if (!sizeOfFilesCreatedOnDate.TryGetValue(date, out size))
{
size = 0;
}
sizeOfFilesCreatedOnDate[date] = size + fileInfo.Length;
}
// Recursively tally each child directory in the parent directory
foreach (string childDirectory in Directory.GetDirectories(directory))
{
AddDirectoryContents(childDirectory, ref sizeOfFilesCreatedOnDate);
}
}
}
using System.Collections.Generic;
using System.IO;
class SizeOfFilesCreatedOnDate
{
private const string outputFileName = "SizeOfFilesCreatedOnDate.csv";
static void Main(string[] args)
{
// Create a dictionary to hold the date/size pairs (sorted for subsequent output)
SortedDictionary<DateTime, long> sizeOfFilesCreatedOnDate = new SortedDictionary<DateTime, long>();
// Tally the contents of each specified directory
// * If no command-line argument was given, default to the current directory
if (0 == args.Length)
{
args = new string[] { Environment.CurrentDirectory };
}
foreach (string directory in args)
{
AddDirectoryContents(directory, ref sizeOfFilesCreatedOnDate);
}
// Output all date/size pairs to a CSV file in the current directory
using (StreamWriter writer = File.CreateText(outputFileName))
{
writer.WriteLine("Date,Size,Cumulative");
long cumulative = 0;
foreach (DateTime date in sizeOfFilesCreatedOnDate.Keys)
{
long size = sizeOfFilesCreatedOnDate[date];
cumulative += size;
writer.WriteLine("{0},{1},{2}", date.ToShortDateString(), size, cumulative);
}
}
Console.WriteLine("Output: {0}", outputFileName);
}
private static void AddDirectoryContents(string directory, ref SortedDictionary<DateTime, long> sizeOfFilesCreatedOnDate)
{
// Display status
Console.WriteLine("Scanning: {0}", directory);
// Tally each child file in the parent directory
foreach (string file in Directory.GetFiles(directory))
{
// Get a FileInfo for the file
FileInfo fileInfo = new FileInfo(file);
// Get the creation time of the file
// * If last write < creation, then the file was moved at least once; use the earlier date
// * The difference between local/UTC (~hours) is unimportant at this scale (~years); use local
DateTime date = fileInfo.CreationTime.Date;
if (fileInfo.LastWriteTime.Date < date)
{
date = fileInfo.LastWriteTime.Date;
}
// Update the relevant date/size pair
long size;
if (!sizeOfFilesCreatedOnDate.TryGetValue(date, out size))
{
size = 0;
}
sizeOfFilesCreatedOnDate[date] = size + fileInfo.Length;
}
// Recursively tally each child directory in the parent directory
foreach (string childDirectory in Directory.GetDirectories(directory))
{
AddDirectoryContents(childDirectory, ref sizeOfFilesCreatedOnDate);
}
}
}
Notes:
- I wrote this code for a simple one-time purpose, so there's no fancy/friendly user interface.
- There's also no error-checking. In particular, if it bumps into a directory/file that it doesn't have permission to access, the resulting UnauthorizedAccessException will bubble up and terminate the process. (While this is unlikely to occur when using the program for its intended purpose of examining your data files, it is pretty likely to occur if playing around and pointing it at C:\.)
- Other than adding comments and support for specifying multiple directories on the command-line, this is the same code I used to generate my chart.
- The code for handling last write time being earlier than creation time was something I discovered a need for experimentally when I noticed that considering only creation time reported that none of my files were older than a couple of years. Apparently when I moved stuff around a couple of years ago, the copy to my current drive preserved the file's last write time, but reset its creation time (perhaps because of the FAT->NTFS transition).
Enjoy!